
It’s not hyperbole to say that Zen saved AMD. The fully redesigned CPU architecture, first launched in 2017, swept away all the company’s past mistakes and along with chiplets, Infinity Fabric, and 3D V-cache, it paved the way to profitability and market-leading performance. There have been some big steps forward in the chip design since then but with the freshly announced Zen 5 at Computex 2024, AMD isn’t doing anything majorly different—just a collection of small changes that combine to give some notable performance boosts, in the right applications.
Let’s start with what hasn’t changed. Zen 5 is fundamentally the same as Zen 4, with the CCDs (Core Complex Dies) comprising up to eight cores, sharing 32MB of L3 cache. The IOD (Input/Output Die) is practically the same, too, although few details about its feature set have been released so far.
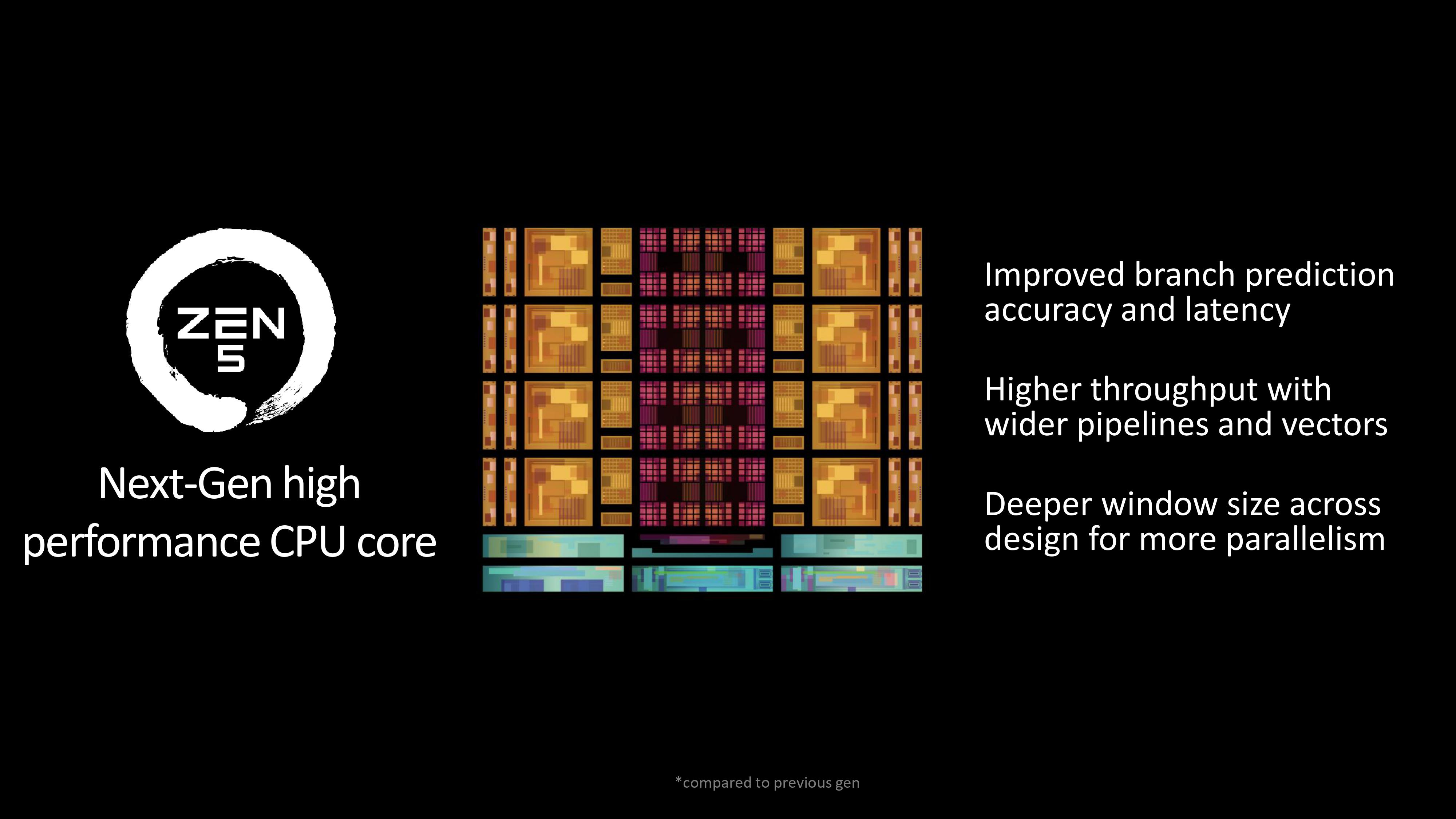
So, you’re not getting any more cores, threads, or cache in Zen 5 compared to Zen 4. That may disappoint some folks but given that there was little to complain about the previous architecture, there wasn’t much call for any sweeping changes to be implemented.
What is new, though, lies deep within the core structures themselves and it mostly revolves around getting more data to where it needs to be, while improving the overall efficiency of a CCD’s number-crunching ability. The Zen 5 announcement is quite light on specifics, but here’s what we’ve been told.
Each core’s branch prediction unit has been tweaked to make it more accurate and spit out results quicker. This circuit is responsible for determining what instructions are most likely to be next in line for a core to process, and the rest of the core then fetches the necessary data and instructions from caches based on what the predictor calculates. If it gets it wrong, then precious cycles are wasted in getting the right information.
Thus a branch predictor that’s more accurate and responds faster means the overall efficiency of the processing side of the chip is better, so nothing to complain about or criticise there.
Zen 5 also sports “wider pipelines and vectors” but without knowing exactly what AMD is referring to here, it’s hard to identify what’s precisely changed compared to Zen 4. Traditionally, a wider pipeline means the sequence of logic units that process instructions can handle larger data formats, but in this case, AMD probably means that Zen 5 has more pipelines (or ports, to use the correct term), more instruction schedulers, and the ability to dispatch more instruction per cycle in each core.
This tallies with the statement that Zen 5 also has a “deeper window size” which almost certainly refers to the reorder buffer (ROB). This is a bit of hardware that lies between the front end of the core (responsible for decoding instructions, renaming them, dispatching micro-operations, etc) and the execution stage, which contains the pipelines.
Image 1 of 8




The job of the reorder buffer is to keep track of what instructions are currently being worked on in the pipelines until they’re finished. AMD has increased the size of the ROB across successive generations of Zen, so it’s not surprising to see it bigger in Zen 5.
Larger ROBs help to prevent the pipelines from being left idle so without this improvement, the ‘wider pipelines’ change wouldn’t be as effective. All of this is good news for performance, but it assumes that the rest of the core has also been improved.
AMD’s other statements suggest that this is the case, highlighting that Zen 5 has up to two times more instruction bandwidth in the front end and the same increase between the L1 data cache and the floating point (aka vector) pipelines, as well as between the L2 and L1 caches.
The phrase ‘up to’ is a bit odd. Ordinarily, if one doubles the width of a data bus and keeps the clock speeds the same, then the effective bandwidth is double. Perhaps it’s marketing speak to prevent anyone from pointing out that it’s not exactly twice as much, but who knows at this stage?
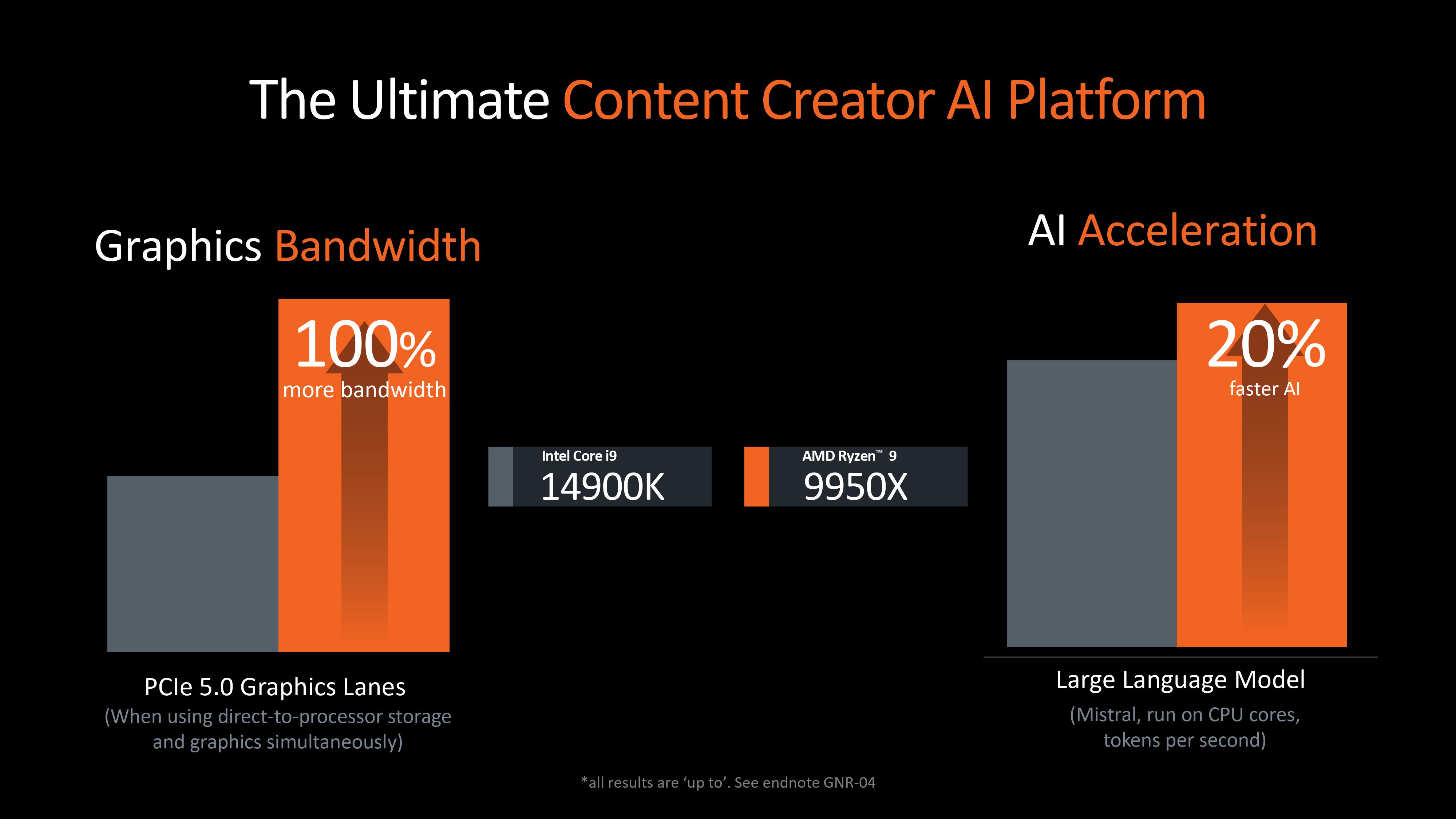
Anyway, for professionals doing serious content creation, AI routines, and other tasks that involve mega-heavy vector operations, up to two times more “AI and AVX-512 throughput” will be especially welcome. Zen 4 was AMD’s first architecture to support the AVX-512 extension, so improvements here were expected, but if the speed of such operations has doubled, then Zen 5 will be lapped up in the pro market.
AMD’s Zen 5 announcement comes across as rather unstated, with just two slides on the core changes, and nothing at all has been said about the Input/Output die. That leaves one to assume it’s unchanged but given that the Ryzen 9000 series in an X870 motherboard supports higher RAM speeds than the 7000 series in an X670 motherboard, something must have been updated.
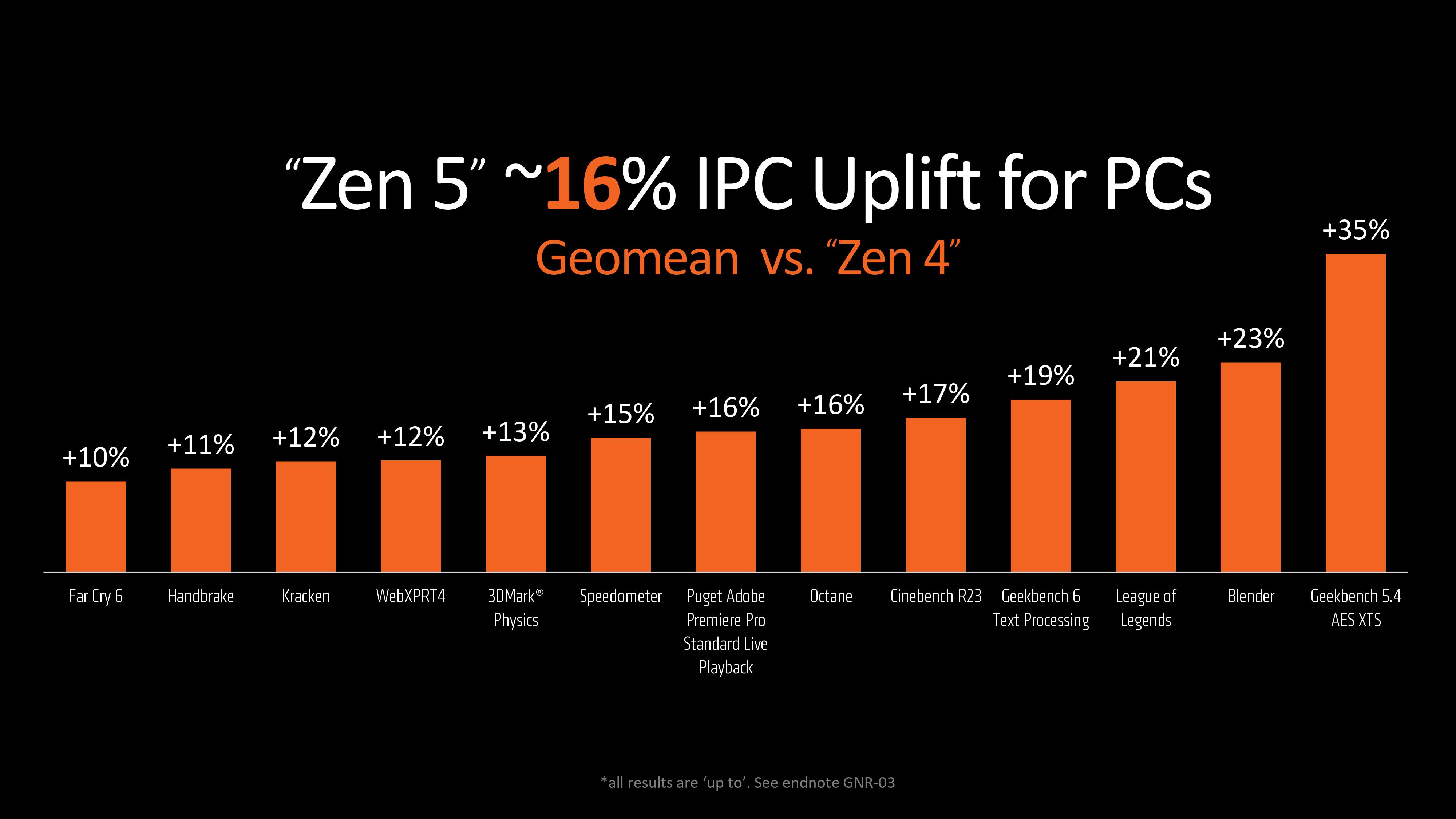
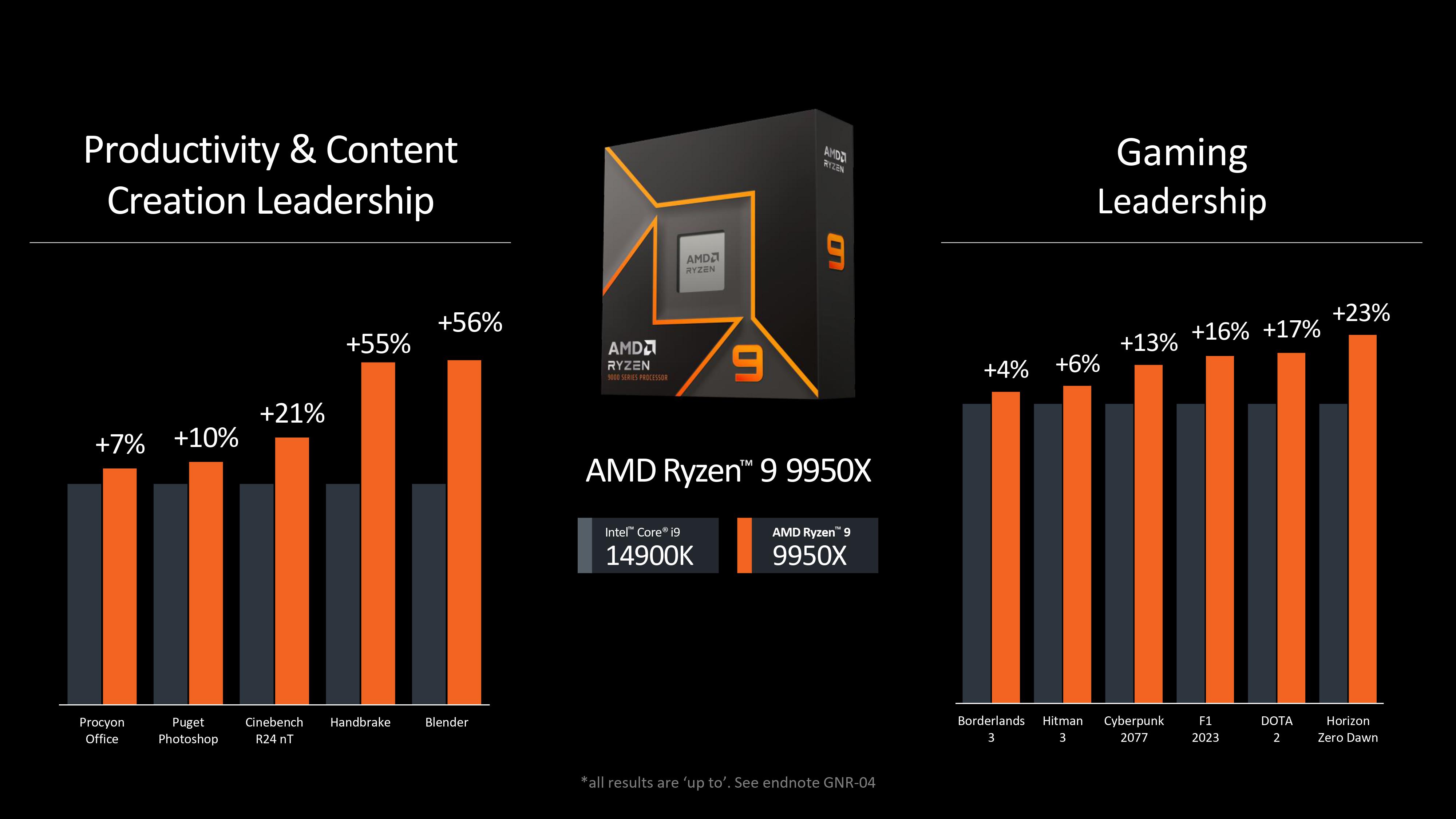
More importantly, when you’re getting up to 23% more performance in Blender compared to Zen 4 at the same clock speed, it’s clear that the improvements are very significant.
Games are far less sensitive to IPC (instruction per cycle) increases, as they’re more dependent on cache and memory, but still, a 21% higher frame rate in League of Legends, even 10% in Far Cry 6, isn’t to be dismissed lightly.
It’s a shame that more details about the architecture are being held back for a future event but at least we won’t have to wait very long for independent analysts to examine AMD’s claims, as the first chips to be based on the new design, the Ryzen 9000 series, will be coming in July.