
Running any scalable distributed platform demands a commitment to reliability, to ensure customers have what they need when they need it. The dependencies could be rather intricate, especially with a platform as big as Roblox. Building reliable services means that, regardless of the complexity and status of dependencies, any given service will not be interrupted (i.e. highly available), will operate bug-free (i.e. high quality) and without errors (i.e. fault tolerance).
Why Reliability Matters
Our Account Identity team is committed to reaching higher reliability, since the compliance services we built are core components to the platform. Broken compliance can have severe consequences. The cost of blocking Roblox’s natural operation is very high, with additional resources necessary to recover after a failure and a weakened user experience.
The typical approach to reliability focuses primarily on availability, but in some cases terms are mixed and misused. Most measurements for availability just assess whether services are up and running, while aspects such as partition tolerance and consistency are sometimes forgotten or misunderstood.
In accordance with the CAP theorem, any distributed system can only guarantee two out of these three aspects, so our compliance services sacrifice some consistency in order to be highly available and partition-tolerant. Nevertheless, our services sacrificed little and found mechanisms to achieve good consistency with reasonable architectural changes explained below.
The process to reach higher reliability is iterative, with tight measurement matching continuous work in order to prevent, find, detect and fix defects before incidents occur. Our team identified strong value in the following practices:
- Right measurement – Build full observability around how quality is delivered to customers and how dependencies deliver quality to us.
- Proactive anticipation – Perform activities such as architectural reviews and dependency risk assessments.
- Prioritize correction – Bring higher attention to incident report resolution for the service and dependencies that are linked to our service.
Building higher reliability demands a culture of quality. Our team was already investing in performance-driven development and knows the success of a process depends upon its adoption. The team adopted this process in full and applied the practices as a standard. The following diagram highlights the components of the process:
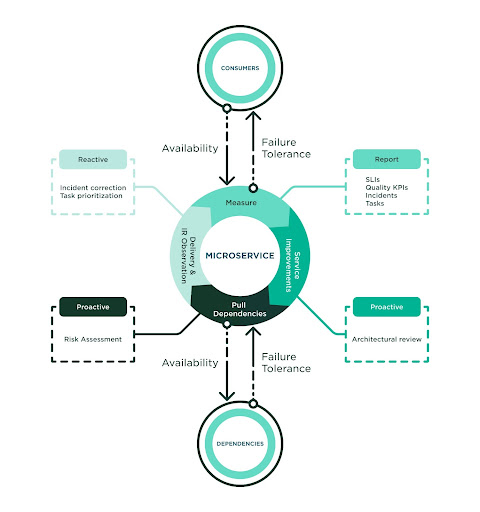
The Power of Right Measurement
Before diving deeper into metrics, there is a quick clarification to make regarding Service Level measurements.
- SLO (Service Level Objective) is the reliability objective that our team aims for (i.e. 99.999%).
- SLI (Service Level Indicator) is the achieved reliability given a timeframe (i.e. 99.975% last February).
- SLA (Service Level Agreement) is the reliability agreed to deliver and be expected by our consumers at a given timeframe (i.e. 99.99% a week).
The SLI should reflect the availability (no unhandled or missing responses), the failure tolerance (no service errors) and quality attained (no unexpected errors). Therefore, we defined our SLI as the “Success Ratio” of successful responses compared to the total requests sent to a service. Successful responses are those requests that were dispatched in time and form, meaning no connectivity, service or unexpected errors happened.
This SLI or Success Ratio is collected from the consumers’ point of view (i.e., clients). The intention is to measure the actual end-to-end experience delivered to our consumers so that we feel confident SLAs are met. Not doing so would create a false sense of reliability that ignores all infrastructure concerns to connect with our clients. Similar to the consumer SLI, we collect the dependency SLI to track any potential risk. In practice, all dependency SLAs should align with the service SLA and there is a direct dependency with them. The failure of one implies the failure of all. We also track and report metrics from the service itself (i.e., server) but this is not the practical source for high reliability.
In addition to the SLIs, every build collects quality metrics that are reported by our CI workflow. This practice helps to strongly enforce quality gates (i.e., code coverage) and report other meaningful metrics, such as coding standard compliance and static code analysis. This topic was previously covered in another article, Building Microservices Driven by Performance. Diligent observance of quality adds up when talking about reliability, because the more we invest in reaching excellent scores, the more confident we are that the system will not fail during adverse conditions.
Our team has two dashboards. One delivers all visibility into both the Consumers SLI and Dependencies SLI. The second one shows all quality metrics. We are working on merging everything into a single dashboard, so that all of the aspects we care about are consolidated and ready to be reported by any given timeframe.
Anticipate Failure
Doing Architectural Reviews is a fundamental part of being reliable. First, we determine whether redundancy is present and if the service has the means to survive when dependencies go down. Beyond the typical replication ideas, most of our services applied improved dual cache hydration techniques, dual recovery strategies (such as failover local queues), or data loss strategies (such as transactional support). These topics are extensive enough to warrant another blog entry, but ultimately the best recommendation is to implement ideas that consider disaster scenarios and minimize any performance penalty.
Another important aspect to anticipate is anything that could improve connectivity. That means being aggressive about low latency for clients and preparing them for very high traffic using cache-control techniques, sidecars and performant policies for timeouts, circuit breakers and retries. These practices apply to any client including caches, stores, queues and interdependent clients in HTTP and gRPC. It also means improving healthy signals from the services and understanding that health checks play an important role in all container orchestration. Most of our services do better signals for degradation as part of the health check feedback and verify all critical components are functional before sending healthy signals.
Breaking down services into critical and non-critical pieces has proven useful for focusing on the functionality that matters the most. We used to have admin-only endpoints in the same service, and while they were not used often they impacted the overall latency metrics. Moving them to their own service impacted every metric in a positive direction.
Dependency Risk Assessment is an important tool to identify potential problems with dependencies. This means we identify dependencies with low SLI and ask for SLA alignment. Those dependencies need special attention during integration steps so we commit extra time to benchmark and test if the new dependencies are mature enough for our plans. One good example is the early adoption we had for the Roblox Storage-as-a-Service. The integration with this service required filing bug tickets and periodic sync meetings to communicate findings and feedback. All of this work uses the “reliability” tag so we can quickly identify its source and priorities. Characterization happened often until we had the confidence that the new dependency was ready for us. This extra work helped to pull the dependency to the required level of reliability we expect to deliver acting together for a common goal.
Bring Structure to Chaos
It is never desirable to have incidents. But when they happen, there is meaningful information to collect and learn from in order to be more reliable. Our team has a team incident report that is created above and beyond the typical company-wide report, so we focus on all incidents regardless of the scale of their impact. We call out the root cause and prioritize all work to mitigate it in the future. As part of this report, we call in other teams to fix dependency incidents with high priority, follow up with proper resolution, retrospect and look for patterns that may apply to us.
The team produces a Monthly Reliability Report per Service that includes all the SLIs explained here, any tickets we have opened because of reliability and any possible incidents associated with the service. We are so used to generating these reports that the next natural step is to automate their extraction. Doing this periodic activity is important, and it is a reminder that reliability is constantly being tracked and considered in our development.

Our instrumentation includes custom metrics and improved alerts so that we are paged as soon as possible when known and expected problems occur. All alerts, including false positives, are reviewed every week. At this point, polishing all documentation is important so our consumers know what to expect when alerts trigger and when errors occur, and then everyone knows what to do (e.g., playbooks and integration guidelines are aligned and updated often).
Ultimately, the adoption of quality in our culture is the most critical and decisive factor in reaching higher reliability. We can observe how these practices applied to our day-to-day work are already paying off. Our team is obsessed with reliability and it is our most important achievement. We have increased our awareness of the impact that potential defects could have and when they could be introduced. Services that implemented these practices have consistently reached their SLOs and SLAs. The reliability reports that help us track all the work we have been doing are a testament to the work our team has done, and stand as invaluable lessons to inform and influence other teams. This is how the reliability culture touches all components of our platform.
The road to higher reliability is not an easy one, but it is necessary if you want to build a trusted platform that reimagines how people come together.
Alberto is a Principal Software Engineer on the Account Identity team at Roblox. He’s been in the game industry a long time, with credits on many AAA game titles and social media platforms with a strong focus on highly scalable architectures. Now he’s helping Roblox reach growth and maturity by applying best development practices.